When you hear the term “machine learning,” do you think to yourself, “How does machine learning really work?” Well, machine learning uses historical data, and what I mean by this is past data. This data could be from databases, Hadoop systems, CSV format, or streaming data from a social media website.
Why Do We Need Machine Learning?
To use machine learning, we need a physical use case—and there are millions of them. It can be soccer players running down a field, people walking into a store, the main word searched on your website today, or any other physical use case. What we need to do is collect data on that given particular use case, and as I mentioned, we can have the data natively or maybe stream it into a data lake. There are many options.
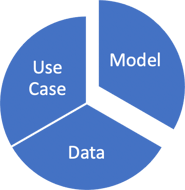
We then need to combine that data set with some kind of machine learning model, and we do not necessarily know which model we are going to use upfront. There will be some significant experimentation that will go into the process.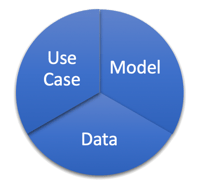 We want our data set and model to reflect the real-world use case. There is an element of intuition here. We want both our data and model to actually balance, so if we are using too many layers of depth on our tree with XGBOOST or if we are not keeping parameters in check, then our model can get too large and cause overfitting. This will cause the model to learn too closely and not be able to generalize very well, as in the image below.
We want our data set and model to reflect the real-world use case. There is an element of intuition here. We want both our data and model to actually balance, so if we are using too many layers of depth on our tree with XGBOOST or if we are not keeping parameters in check, then our model can get too large and cause overfitting. This will cause the model to learn too closely and not be able to generalize very well, as in the image below.
And flipping this over, if our data set is too large and the model is not large enough to handle this, then we will see underfitting.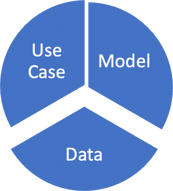
Breaking Down the Points of Consideration
- The first consideration is: What data do I have on this use case?
- Which machine learning model should I use?
- How do I frame the problem and map them?
Each Algorithm Solves a Type of Prediction Problem
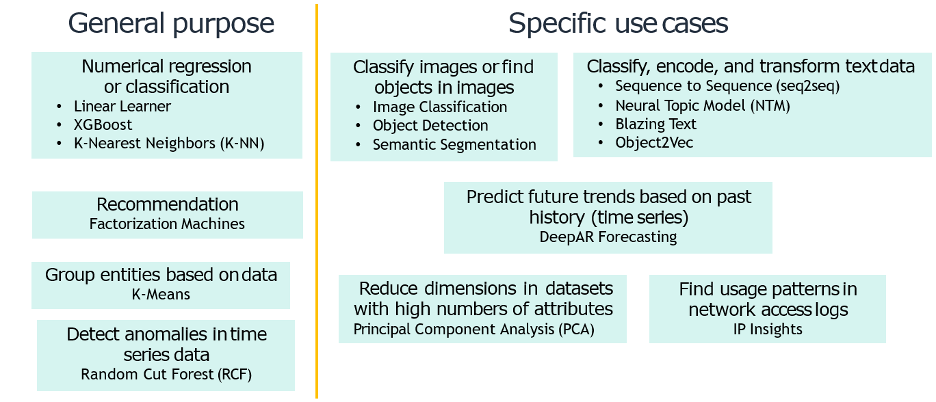
In the image below are the supported algorithms built into Amazon Sagemaker.
Algorithms are standardized methods used to train models. A model is a function that maps inputs to a set of predicted outcomes using algorithms. Existing data is then used to build a function using rules, and this is called training. With training, we can ensure that machine learning is applicable to real-world use cases and will provide valuable insights.
For further information, reach out to ConvergeOne.

Topics: Data Center, Artificial Intelligence, Machine Learning



